We are excited to announce the public beta launch of Foursquare’s Batch Place Match API, a collection of endpoints that bring Foursquare’s cutting-edge entity resolution capabilities directly to your data pipelines. Whether you’re a logistics company verifying delivery addresses, a financial services firm categorizing transaction merchants, or a marketing platform building audience segments based on real-world visits, accurate POI (point-of-interest) matching is the crucial first step. Without it, your data remains fragmented across sources, riddled with duplicates, and missing the rich attributes needed to power meaningful insights. The Batch Place Match API solves this pain point by enabling you to match your POI records against Foursquare’s authoritative dataset of 100+ million global places, linking your data via the Foursquare Place ID and unlocking access to 60+ rich attributes including photos, hours, and ratings.
Leveraging modern NLP techniques, specifically transformer models, the Batch Place Match API tackles POI matching (also referred to as “harmonization”) with high accuracy and efficiency. By transforming disparate POI data into contextual embeddings, it can identify and link real-world places more effectively than with traditional methods. This blog post covers how the Batch Place Match API overcomes common challenges in POI matching, from handling data inconsistencies to understanding semantic relationships between locations.
The POI Matching Problem
POI matching is the process of linking different representations of the same real-world place. It sounds simple, but consider: “Starbucks, 123 Main St, New York” and “Starbucks Coffee, 123 Main Street, NYC” are the same location, while “Starbucks, 123 Main St” and “Starbucks, 321 Main St” are not. When organizations ingest data from multiple providers, each source refers to places with different spellings, addresses, and metadata, making accurate matching essential for building a unified, deduplicated view of the world.
POI matching is an inherently difficult problem to solve due to complexities including but not limited to:
- Scale: To match a query POI, you have to search the space of all potential matches, which can be computationally intensive, especially at the global POI scale of Places data at Foursquare.
- Attribute inaccuracy/unavailability: POI attributes, such as geocodes, can have inaccuracies or not be populated at all, which can lead to missed or inaccurate matches.
- Text data messiness: Even when the attribute has the correct value, the data can be messy and suffer from issues such as inconsistent formatting.
- Multilinguality: Given Foursquare’s global scale, POI data is inherently multilingual, requiring the model to handle and match places across different languages and character sets.
- Geographical and cultural variations: POIs are referenced differently across countries, including varying naming conventions, address formats, and the presence or absence of specific attributes such as building numbers. This requires models to be adaptable to diverse data structures and cultural nuances.
- The sub-venue problem: Referring to one or multiple sub-venues being located inside one larger venue, e.g. Walmart Bakery should not be matched to Walmart at the same address.
Traditional approaches consistently fail to handle these complexities. For example, geoblocking, an approach that involves filtering candidates to only those within a certain radius of the query POI, breaks down when geocodes are inaccurate or missing. Traditional NLP features like string similarity struggle with formatting variations and multilingual data. This drove us to build a more sophisticated, AI-powered solution, which is exactly what powers the Batch Place Match API.
Under the Hood: How the Batch Place Match API Works
The Batch Place Match API uses a two-stage approach: first, a retrieval stage to efficiently identify candidate matches from millions of POIs, and, second, a reranking stage to precisely score and select the best match. Both stages are powered by models fine-tuned specifically for POI data.
Preparing and Indexing 100M+ POIs
Before matching, attributes of each POI record in our database are concatenated into a single string that looks something like “California Pizza Kitchen 123 Main St New York NY”. This consolidated text serves as an input into a Sentence Transformer model, which generates a dense vector embedding that captures the semantic meaning of the entire POI. Embeddings are pre-computed for the 100 million+ records in our database and indexed using FAISS (Facebook AI Similarity Search), enabling fast nearest-neighbor lookups. When a query POI arrives, its embedding is compared against this pre-built index in milliseconds rather than requiring a brute-force search across the entire dataset.
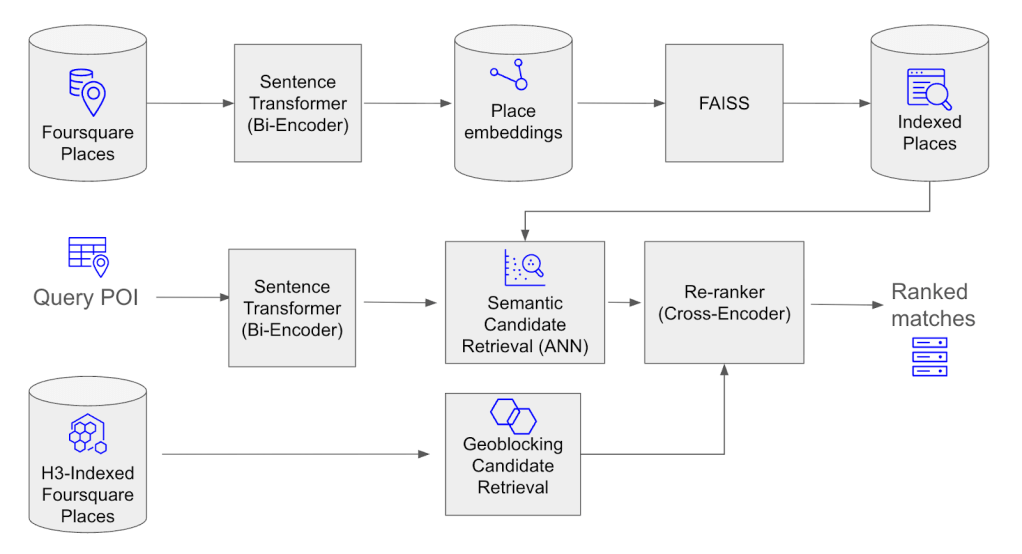
Stage 1: Candidation Generation
The retrieval stage uses two complementary methods to identify candidate matches:
- Embedding-based retrieval computes the query POI’s embedding and uses FAISS to retrieve the top-10 candidates with the most similar vectors. This approach excels at handling text variations, abbreviations, and semantic similarities that would trip up exact-match systems.
- Geoblocking supplements this by searching within a 1,000-meter radius of the query POI’s geocode using H3-indexed data, combined with fuzzy name matching. This catches cases where the approximate nearest-neighbor search might miss a true match.
Importantly, geoblocking is optional, the system still performs well when geocodes are missing or inaccurate, relying on the semantic strength of the embeddings alone.
Stage 2: Best Match Selection
The candidates from retrieval are then scored by a cross-encoder model. Unlike the retrieval stage, which computes embeddings independently, the cross-encoder evaluates the query and each candidate as a pair. This allows it to capture fine-grained interactions between the two POIs, detecting subtle signals that distinguish a true match from a near-miss. The candidate with the highest score is returned as the best match.
We fine-tune our models in both stages on a curated dataset of known matching and non-matching POI pairs drawn from Foursquare’s data. This training teaches the model the specific nuances of POI matching such as handling chain variations, sub-venues, multilingual names, and address formatting differences, resulting in significantly better precision and recall than generic pre-trained models.
This two-stage design balances efficiency and precision: retrieval quickly narrows millions of POIs down to a handful of candidates and reranking applies more computational power to make the final, high-confidence decision.
Battle-Tested in Foursquare’s Places Engine
The Batch Place Match API is powered by the same harmonization system that runs at the core of Foursquare’s Places Engine. As we ingest data from hundreds of sources, the matching system resolves each input against our existing dataset—linking matches to update and enrich existing records, or creating new POIs when no match is found. This process keeps our 100+ million POIs accurate, complete, and fresh.
When the model produces low-confidence outputs, we route those cases to Placemaker Tools, our crowdsourcing platform where human contributors validate ambiguous matches. These sources of ground truth flow back into our training pipeline, continuously improving model accuracy over time. The Batch Place Match API gives you access to this same production-grade system.
Evaluation & Results
We measure performance using precision (the proportion of returned matches that are correct) and recall (the proportion of true matches that we successfully identify). For the retrieval stage specifically, we track Recall@10, whether the correct match appears in the top 10 candidates passed to the reranker. This separation allows us to independently optimize retrieval effectiveness and reranking accuracy.
The system maintains 95%+ precision while resolving hundreds of thousands of entities that previously required manual verification. A key goal was improving robustness when geocodes are missing or inaccurate—a common real-world challenge. We benchmarked specifically against data which exhibits these imperfections. Compared to our previous system, we observed a 15% increase in Recall@10 and a 10% increase in Recall at 0.95 Precision, demonstrating the model’s ability to match effectively even without accurate location data.
Why a Batch API?
POI matching often happens as part of larger data engineering workflows such as nightly jobs that reconcile transaction feeds, periodic refreshes that merge data from new providers, or one-time migrations consolidating legacy databases. The Batch Place Match API is designed to fit naturally into these pipelines, allowing you to submit millions of records and retrieve results asynchronously without managing rate limits or building retry logic.
To use the API, you provide a dataset of your places via S3 bucket. Each record must include a unique id, name, address, city, state, and country. Additional attributes like postal code or location coordinates can improve match accuracy but are not required. The API processes your dataset and returns an output dataset containing, for each input row, the matched Foursquare Place ID (if any), standardized address details, and a match bucket indicating our confidence level.
Match buckets classify each result into one of four categories: definite match (matched with highest confidence), likely match (high likelihood of being correct), need more info (additional information required to determine status), or not a match (no match identified). This tiered output enables you to automate high-confidence matches while flagging uncertain cases for review.
Looking ahead, we plan to extend the Batch API to support human-in-the-loop verification for ambiguous cases, similar to how Foursquare handles matching internally with Placemaker Tools. The batch workflow makes this possible: automatically accept definite matches, route “need more info” cases to reviewers, and reject clear non-matches.
Join the Public Beta
The Batch Place Match API brings Foursquare’s production-grade harmonization system—powered by transformer models and a two-stage retrieval-reranking approach—directly to your data pipelines. By leveraging contextual embeddings, the API handles the real-world messiness of POI data: inconsistent formatting, missing geocodes, multilingual names, and geographic variations. The result of the Batch Place Match API is accurate, high-confidence matching at scale.
Whether you’re enriching transaction data, consolidating merchant databases, or building location-aware applications, the Batch Place Match API provides the foundation for a unified view of real-world places. The Batch Place Match API is now available in public beta. Check out the API docs to learn more, or contact us to join the beta.